ParamSpider
→ View on GitHubAI Summary: ParamSpider is a tool designed for fetching and filtering URLs from Wayback Machine archives, specifically targeting domains for bug hunting, fuzzing, and further probing. Its notable features include the ability to ignore less relevant URLs, support for multiple domains, proxy configuration, and the option to introduce placeholders for parameter values, enhancing the efficiency of security assessments.
README
paramspider
Mining URLs from dark corners of Web Archives for bug hunting/fuzzing/further probing
📖 About • 🏗️ Installation • ⛏️ Usage • 🚀 Examples • 🤝 Contributing •
About
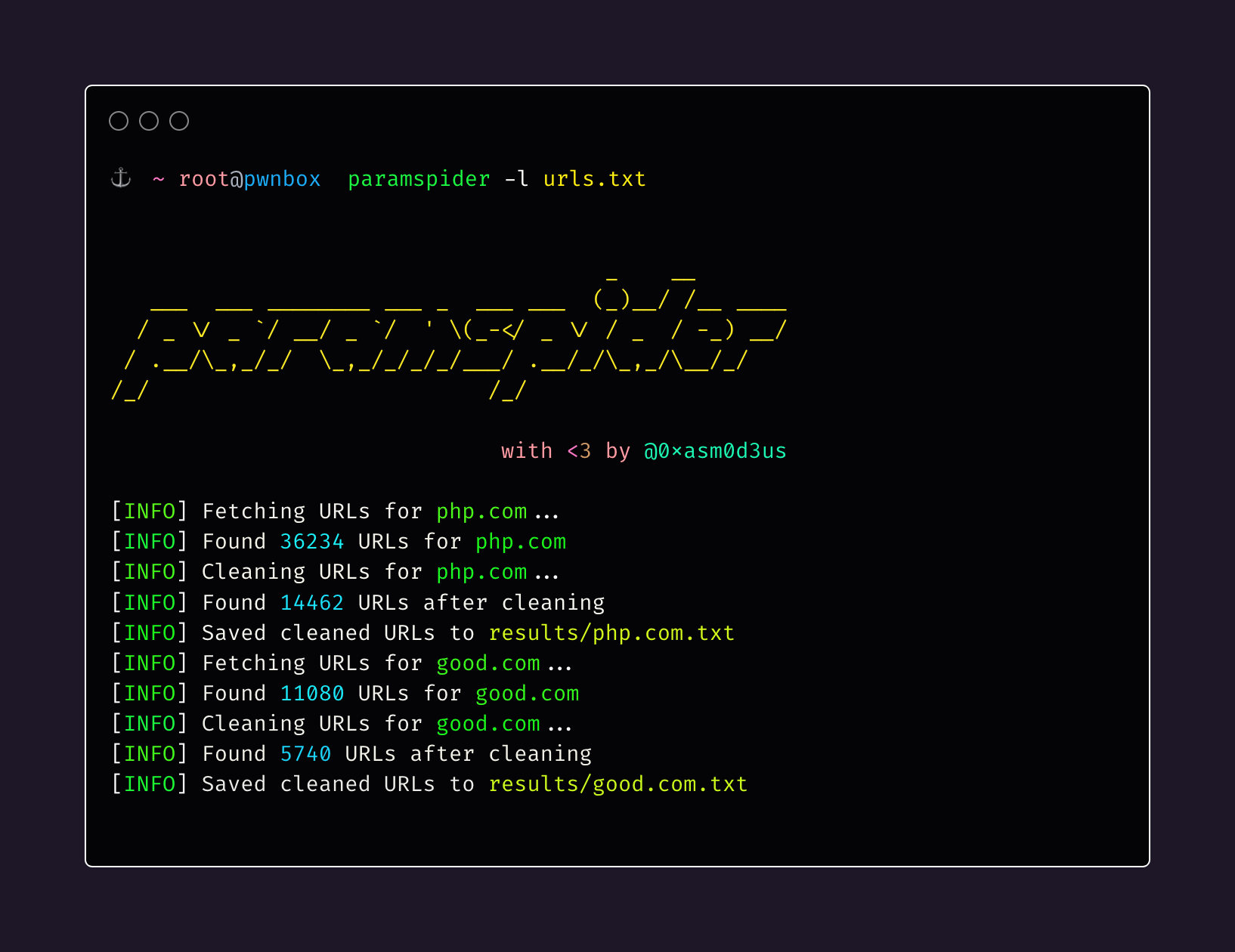
paramspider allows you to fetch URLs related to any domain or a list of domains from Wayback achives. It filters out “boring” URLs, allowing you to focus on the ones that matter the most.
Installation
To install paramspider, follow these steps:
git clone https://github.com/devanshbatham/paramspider
cd paramspider
pip install .
Usage
To use paramspider, follow these steps:
paramspider -d example.com
Examples
Here are a few examples of how to use paramspider:
Discover URLs for a single domain:
paramspider -d example.comDiscover URLs for multiple domains from a file:
paramspider -l domains.txtStream URLs on the termial:
paramspider -d example.com -sSet up web request proxy:
paramspider -d example.com --proxy '127.0.0.1:7890'Adding a placeholder for URL parameter values (default: “FUZZ”):
paramspider -d example.com -p '"><h1>reflection</h1>'